Fajzel et al. (2023) shows that the time spent on activities such as Food Growth and Collection is highly dependent on the GDP of the country in question. I therefore decided to cluster the countries according to the time for Food Growth and Collection and GDP. The data on GDP in 2021 comes from Arel-Bundock (2022).
The Code
# Load Required R Libraries # The following libraries are loaded to provide necessary functions and data for the analysis and visualization. library(tidyverse) # For data manipulation and visualization
library(tidytuesdayR) # For accessing TidyTuesday datasets library(showtext) # For working with fonts
library(glue) # For text formatting library(ggtext) # For enhanced text formatting in ggplot2 library(factoextra) # For clustering analysis
library(cluster) # For clustering functions library(patchwork) # For combining multiple plots library(WDI) # For fetching World Development Indicators (WDI) data library(sf) # For working with spatial data
library(rnaturalearth) # For world map data
library(rnaturalearthdata) # For additional world map data
# Load Data # Data is loaded from the 'tidytuesdayR' package for a specific week (2023, week 37). tuesdata <- tidytuesdayR::tt_load(2023, week = 37)
## ## Downloading file 1 of 4: `all_countries.csv` ## Downloading file 2 of 4: `country_regions.csv` ## Downloading file 3 of 4: `global_human_day.csv` ## Downloading file 4 of 4: `global_economic_activity.csv`
# Extract Specific Datasets # Relevant datasets are extracted from the loaded data. all_countries <- tuesdata$all_countries country_regions <- tuesdata$country_regions global_human_day <- tuesdata$global_human_day global_economic_activity <- tuesdata$global_economic_activity # Fetch World Development Indicators (WDI) Data # The code fetches WDI data for Gross Domestic Product (GDP) per capita for the year 2021. # The data is renamed for clarity. wdi <- WDI(indicator='NY.GDP.PCAP.KD', country="all", start=2021, end=2021) %>% rename(country_iso3 = iso3c, GDP = NY.GDP.PCAP.KD) # Load World Country Data # World country data is loaded and stored as a spatial object for mapping purposes. world <- ne_countries(scale = "medium", returnclass = "sf") class(world)
## [1] "sf" "data.frame"
# Load Fonts and Define Colors # Fonts are loaded and colors are defined for text and symbols in visualizations. font_add_google("Playfair Display", "playfair") font_add('fa-reg', 'c:/Users/info/OneDrive/Dokumente/fonts/Font Awesome 6 Free-Regular-400.otf') font_add('fa-brands', 'c:/Users/info/OneDrive/Dokumente/fonts/Font Awesome 6 Brands-Regular-400.otf') font_add('fa-solid', 'c:/Users/info/OneDrive/Dokumente/fonts/Font Awesome 6 Free-Solid-900.otf') showtext_auto() bg <- "white" col1 <- thematic::okabe_ito()[1] col2 <- thematic::okabe_ito()[2] col3 <- thematic::okabe_ito()[3] # Define Symbols # Symbols are defined using HTML-style code with appropriate colors and fonts. twitter <- glue("<span style='color:{col1};font-family:fa-brands;'></span>") mastodon <- glue("<span style='color:{col1};font-family:fa-brands;'></span>") link <- glue("<span style='color:{col1};font-family:fa-solid;'></span>") data <- glue("<span style='color:{col1};font-family:fa-solid;'></span>") quote <- glue("<span style='color:{col1};font-family:fa-solid;'></span>") space <- glue("<span style='color:{bg}'>-</span>") space2 <- glue("<span style='color:{bg}'>--</span>") # This creates horizontal lines for formatting. # Define Title # A formatted title for the analysis is defined using glue. t <- glue("<b>Clustering The World By Time Spent For Food Growth & <br>Collection And GDP Per Capita</b>") # Define Caption # A formatted caption is defined, including social media icons and links. cap <- glue("{twitter}{space2}@web_design_fh{space2} {space2}{mastodon}{space2}@frankhaenel @fosstodon.org{space2} {space2}{link}{space}{space2}www.frankhaenel.de<br> {data}{space2}The{space}Human{space}Chronome{space}Project{space2}|{space2}WDI{space}package<br> {quote}{space2}Fajzel,{space}William,{space}et{space}al.{space}'The{space}global{space}human{space}day'.{space}Proceedings{space}of{space}the{space}National{space}Academy{space}of{space}Sciences,{space}vol.{space}120,{space}no.{space}25,{space}2023.") # Define Cluster Labels # Labels for different clusters are defined. A <- "High GDP, Low Food Growth & Collection" B <- "Low GDP, High Food Growth & Collection" C <- "Moderate GDP, Moderate Food Growth & Collection" # Data Preparation # Data is filtered and joined, handling missing values. df <- all_countries %>% filter(Subcategory == "Food growth & collection") %>% left_join(wdi, by = "country_iso3") %>% na.omit # Elbow Method Plot # The elbow method plot is created to determine the optimal number of clusters. ellbow <- fviz_nbclust(scale(df[,c(6,11)]), kmeans, method = "wss") + theme( plot.title = element_markdown(size = 12, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.subtitle = element_markdown(size = 15, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.caption = element_markdown(size = 9, hjust = 0.5, lineheight = 1.3, color = "lightgrey", family = "playfair"), axis.title = element_markdown(size = 8, color = "darkgrey", family = "playfair"), axis.text = element_markdown(size = 8, color = "darkgrey", family = "playfair")) # Gap Statistic Plot # The gap statistic plot is created to evaluate clustering quality. gap_stat <- clusGap(scale(df[,c(6,11)]), FUN = kmeans, nstart = 25, K.max = 10, B = 50) gap <- fviz_gap_stat(gap_stat) + theme( plot.title = element_markdown(size = 11, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.subtitle = element_markdown(size = 15, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.caption = element_markdown(size = 9, hjust = 0.5, lineheight = 1.3, color = "lightgrey", family = "playfair"), axis.title = element_markdown(size = 8, color = "darkgrey", family = "playfair"), axis.text = element_markdown(size = 8, color = "darkgrey", family = "playfair")) # Seed for Reproducibility # A random seed is set to ensure reproducibility in k-means clustering. set.seed(1) # K-Means Clustering # K-means clustering is performed on the data. km <- kmeans(scale(df[,c(6,11)]), centers = 3, nstart = 25) km
## K-means clustering with 3 clusters of sizes 30, 66, 87 ## ## Cluster means: ## hoursPerDayCombined GDP ## 1 -1.1161476 1.8968843 ## 2 1.1214480 -0.5433786 ## 3 -0.4658752 -0.2418797 ## ## Clustering vector: ## [1] 1 2 2 2 1 3 3 3 1 1 3 2 1 2 3 2 3 3 3 3 3 3 3 3 3 1 2 3 2 1 1 3 2 2 2 2 3 ## [38] 3 2 2 3 3 3 1 3 1 2 1 3 3 3 3 3 3 2 1 2 1 2 2 1 3 2 2 3 2 2 3 3 2 2 3 1 2 ## [75] 3 2 3 2 2 1 3 3 1 1 1 3 3 1 3 3 3 2 2 1 3 2 3 2 3 3 3 3 3 1 3 2 3 2 2 3 3 ## [112] 3 2 1 2 3 2 2 2 3 2 3 3 2 2 2 1 1 3 1 3 3 3 3 3 2 3 3 3 3 3 2 1 2 3 2 3 3 ## [149] 1 2 2 3 2 3 2 3 3 3 1 3 2 2 2 2 3 2 2 3 3 3 2 2 3 3 1 3 3 2 2 2 3 2 2 ## ## Within cluster sum of squares by cluster: ## [1] 33.61329 33.58082 25.02299 ## (between_SS / total_SS = 74.7 %) ## ## Available components: ## ## [1] "cluster" "centers" "totss" "withinss" "tot.withinss" ## [6] "betweenss" "size" "iter" "ifault"
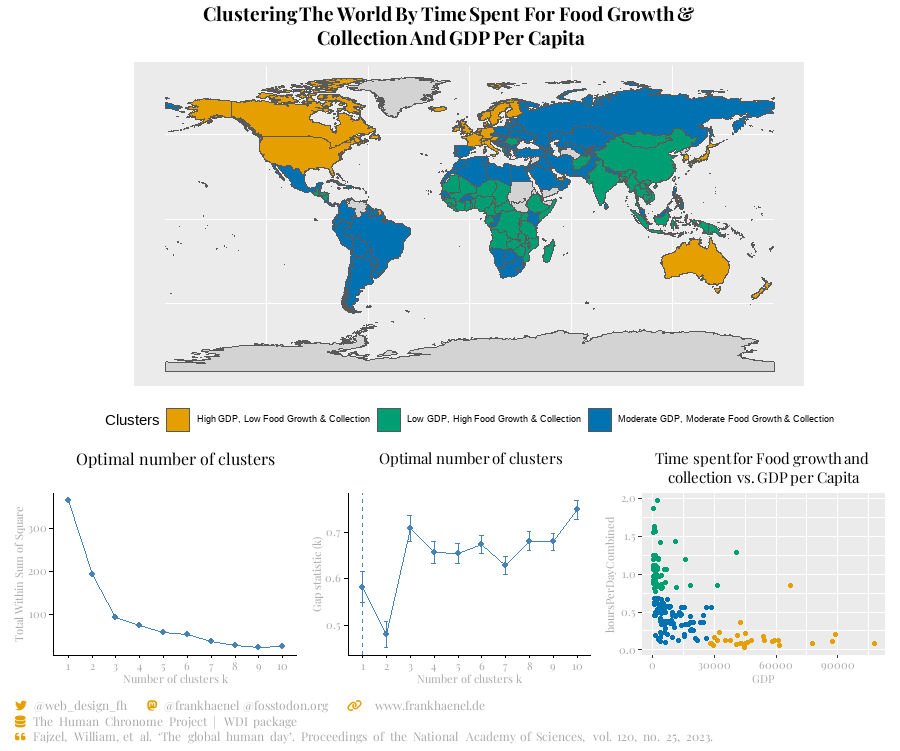
df$cluster <- km$cluster # Scatter Plot # A scatter plot is created to visualize the clustered data. scatter <- ggplot(data=df,aes(x=GDP,y=hoursPerDayCombined,color=as.factor(cluster))) + geom_point(show.legend = F) + scale_color_manual(values = c(col1, col2, col3)) + theme( plot.title = element_markdown(size = 11, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.subtitle = element_markdown(size = 15, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.caption = element_markdown(size = 9, hjust = 0.5, lineheight = 1.3, color = "lightgrey", family = "playfair"), axis.title = element_markdown(size = 8, color = "darkgrey", family = "playfair"), axis.text = element_markdown(size = 8, color = "darkgrey", family = "playfair")) + labs(title = "Time spent for Food growth and <br>collection vs. GDP per Capita") # Choropleth Map # A choropleth map is created to display clustering results on a world map. map <- world %>% rename(country_iso3 = iso_a3) %>% left_join(df, by = "country_iso3") %>% ggplot() + geom_sf(aes(fill = as.factor(cluster)), linewidth = 0.01) + theme(legend.position="bottom") + scale_fill_manual(values=c(col1, col2, col3), name="Clusters", breaks=c("1", "2", "3"), labels=c(A, B, C),na.value = "lightgrey") + theme(legend.text = element_markdown(size = 7)) # Combine Plots # The plots are combined using the 'patchwork' package. a <- ellbow + gap + scatter patchwork <- map / a + plot_layout(heights = c(2, 1)) # Add Plot Annotations and Adjust Theme # Annotations and theme adjustments are applied to the combined plot. patchwork + plot_annotation( subtitle = t, caption = cap ) & theme( plot.subtitle = element_markdown(size = 14, hjust = 0.5, lineheight = 1.3, family = "playfair"), plot.caption = element_markdown(size = 9, hjust = 0, lineheight = 1.3, color = "darkgrey", family = "playfair"))
Documentation
Introduction
This documentation explains the R code used to analyze and visualize data related to time spent on food growth and collection and GDP per capita for different countries. The analysis includes clustering countries based on these factors and presenting the results using various plots and visualizations.
Required Libraries
The code begins by loading several R libraries required for data manipulation, visualization, and font handling. These libraries include:
- tidyverse: For data manipulation and visualization.
- tidytuesdayR: For accessing TidyTuesday datasets.
- showtext: For working with fonts.
- glue: For text formatting.
- ggtext: For enhanced text formatting in ggplot2.
- factoextra and cluster: For clustering analysis.
- patchwork: For combining multiple plots.
- WDI: For fetching World Development Indicators (WDI) data.
- sf, rnaturalearth and rnaturalearthdata: For working with spatial data and world map data.
Data Loading and Preparation
- Data is loaded from the TidyTuesday dataset for a specific week (2023, week 37) using tidytuesdayR::tt_load.
- Specific datasets are extracted from the loaded data, including all_countries, country_regions, global_human_day, and global_economic_activity.
- World Development Indicators (WDI) data for Gross Domestic Product (GDP) per capita for the year 2021 is fetched and renamed for clarity.
- World country data is loaded and stored as a spatial object using the ne_countries function from the rnaturalearth package for mapping purposes.
Fonts and Colors
Fonts are loaded, and colors are defined for text and symbols in visualizations. Font Awesome icons are used for social media symbols.
Symbols Definition
Symbols are defined using HTML-style code with appropriate colors and fonts. Symbols include icons for Twitter, Mastodon, links, data, and quotes
Title and Caption
A formatted title and caption for the analysis are defined using the glue function.
Cluster Labels
Labels for different clusters are defined as A, B, and C.
Data Preparation
Data is filtered and joined, handling missing values. The resulting dataframe is stored as df.
Elbow Method Plot
An elbow method plot is created to determine the optimal number of clusters. It helps in selecting the appropriate number of clusters for k-means clustering.
Gap Statistic Plot
A gap statistic plot is created to evaluate the quality of clustering. It compares the performance of the clustering algorithm for different numbers of clusters.
K-Means Clustering
K-means clustering is performed on the data using the kmeans function. The data is divided into three clusters based on GDP per capita and time spent on food growth and collection.
Scatter Plot
A scatter plot is created to visualize the clustered data, with GDP per capita on the x-axis and time spent on food growth and collection on the y-axis. Each cluster is represented by a different color.
Choropleth Map
A choropleth map is created to display clustering results on a world map. Countries are shaded according to their cluster assignment.
Combine Plots
The plots are combined using the patchwork package to create a single layout containing the elbow method plot, gap statistic plot, scatter plot, and choropleth map.
Plot Annotations and Theme Adjustments
Annotations and theme adjustments are applied to the combined plot, including the title, subtitle, and caption.
Output
The final output is an HTML document containing all the visualizations and annotations created during the analysis. The document provides insights into the clustering of countries based on GDP per capita and time spent on food growth and collection.
References
Fajzel, W., Galbraith, E. D., Barrington-Leigh, C., Charmes, J., Frie, E., Hatton, I. A., Mézo, P. L., Milo, R., Minor, K., Wan, X., Xia, V., & Xu, S. (2023). The Global Human Day. Proceedings of the National Academy of Sciences of the United States of America, 120(25). https://doi.org/10.1073/pnas.2219564120
Arel-Bundock, V. (2022). _WDI: World Development Indicators and Other World Bank Data_. R package version 2.7.8, https://CRAN.R-project.org/package=WDI.